Drupal - Static - Elasticsearch
Export a Drupal site to a static site, along with Elasticsearch
Static sites are the best. They are the most secure and fastest of sites. They are perfect for anonymous users, where you would want content editors to have a secure and hidden backend where they can administer the content - but have the content served elsewhere.
Having search on top of that can be a bit more challenging. There are different solutions for having a local search like lunr.js (and a Drupal module to integrate with it), but it’s quite limited. That is, it will create a local index where you could have some JS to look into it, but that is no match to full-blown search engines such as Elasticsearch.
In this blog post I will share a demo website we’ve built as a proof of concept for a much larger site. I’m not going to dwell on the advantages of static sites, instead I’m going to share the high-level concepts that guided us, along with some technical tips. While the specific details have nothing to do with Drupal - our client’s site is in Drupal, so it was convenient to build it around it. But you can really do it with any language.
Here is the demo repo, and that’s how it looks:
Concepts
With static sites, deploying and reverting deploys is easy. It’s not much more
than git push or git revert if something went wrong. But what about search?
As we’ve mentioned, we want to keep using Elasticsearch for things like
aggregations (a.k.a. facets), spell checks, etc. But how can we support, for
example, a rollback in the deploy - making sure that search is always searching
only through the content that exists in the deployed static site. Thankfully,
Elasticsearch supports index cloning, so we could have something like this:
- We would have a single Elasticsearch instance, that will have multiple indices.
- The
defaultindex is the one that Drupal will connect to, and it will be a read and write. That is, you can think of it as a “master” index, from which a snapshot will be taken. - When we want to create a new static site, we would also create a clone of the default index. That will be a read-only index.
- Our JS app that will be in charge of calling Elasticsearch should know about the name of the read-only index. So if we rollback a deploy to previous versions, the JS code will connect to the right index.
A word about the Elasticsearch instance and its exposure to the outside. In a similar way to how we place Drupal in the backend, away from the public eye, we could do the same with Elasticsearch. For example, when we host Elasticsearch instance(s) on Google Cloud, we can use a load balancer to provide a public-facing, SSLed, URL - which, in turn, will call the Elasticsearch with any kind of firewall rules needed, such as preventing any admin-type requests from hitting the instance, or prevent any request reaching the default index if it doesn’t originate from the Drupal backend.
HTTrack VS wget
We actually started our research looking into Tome, a Drupal module that allows exporting a Drupal site into a static site. While it did work nicely, and I’m sure there could be benefits to using it, I’ve thought that there wasn’t really any specific need in our case for Drupal itself to provide the export. We may as-well use other open source tools, which have been around for quite a few years.
Then started a longer than anticipated trial and comparisons between HTTrack and wget. While we did eventually go with wget it’s worth sharing some of our experience. First we’ve tried HTTrack. We have already used it to help us move some old sites to be static, and it did the job well. The amazing Karen Stevenson also wrote a great post about it that goes into more details. My impression from HTTrack is that it works surprisingly well for a tool that has a site that looks as outdated as it looks. Documentation is pretty good, although at times lacking with concrete examples.
One important thing we’ve done from the get go was take as example a real client site. This immediately manifested the biggest challenge - exporting a static site quickly. Normally, when archiving some site, it’s totally fine for the export to take even an hour. But if we’re thinking of a live site, that regularly updates as content in the backend is changed - having to wait so long is problematic.
This is where we were jumping back and forth between HTTrack and wget. Let’s see some of the results we got. I’m going to hide the real URL, so you won’t abuse our client’s site as much as we did! :)
httrack https://example.com -O . -N "%h%p/%n/index%[page].%t" -WqQ%v --robots=0 --footer ''

37 minutes for about 450 MB of saved content (HTML along with all the assets, images, and files).
That attempt was on my local computer. So we spun up a Google Cloud instance, to see if executing this from a server with a more powerful internet connection would be much faster - but it wasn’t.
So we decided to exclude all user-generated files (images, PDFs, etc). The idea would be that files would be uploaded to some storage service like AWS or Google Cloud and be served from there. That is, when a content editor will upload a new file in Drupal, instead of saving it on the server, it will be saved “remotely.”
httrack https://example.com -N "%h%p/%n/index%[page].%t" --display --robots=0 "-*.pdf" "-*.zip" "-*.jpg" "-*.gif" "-*.png"
Doing so shaved quite a lot, and got us down to 20 minutes with 120 MB.
Then we checked if we could increase the number of concurrent connections.
HTTrack has a few options, notably the scarily-named --disable-security-limits
that should allow us to lightly DDOS our own site, or by setting a specific
count of connections (e.g. -c16). However, we didn’t seem to see a change in
the number of connections.
Then we tried to update an existing static site by executing httrack --update. This one was already considerably faster, and got us down to 4.5
minutes, and this time we also saw multiple active connections.
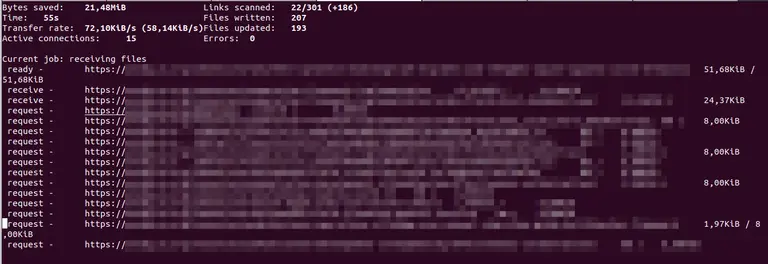
After that I started looking into wget, running wget --recursive --page-requisites --adjust-extension --span-hosts --convert-links --restrict-file-names=windows --domains example.com --no-parent --reject jpg,jpeg,png,zip,pdf,svg https://example.com/ (see
gist
for explanation on each option).
First grab took only 8 minutes, x3 faster than HTTrack! Update took about 5 minutes.
After spending many hours digging in different forums and StackOverflow, I’ve decided to go with wget, but I do think HTTrack should be considered if you go with a similar solution. I believe it’s a “your mileage may vary” situation.
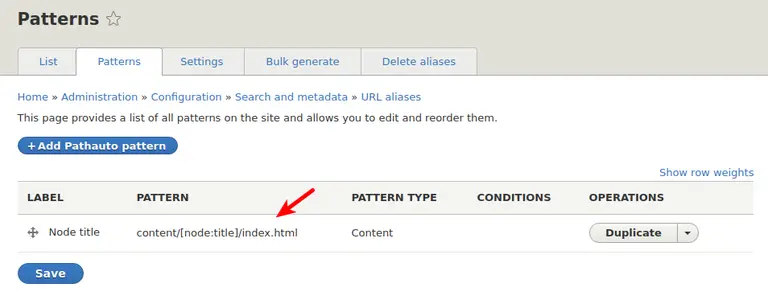
One shortcoming I found with wget, was that unlike HTTrack I couldn’t tell it
under what name to save the HTML file. Instead of /content/foo/index.html I
got the file as /content/foo.html. Do you know how I solved it? With a hack
equally nice as it’s ugly. On Drupal I’ve changed the path aliases pattern to
be /content/[node:title]/index.html. I hope maybe someone will point me to a way of
getting wget to do it for us.
Bundle Everything Together
My personal belief is that technical posts should put in the hands of their readers the means to get their hands dirty, experiment, and collaborate. So here you go, and here’s the recipe for the demo repo:
It was scaffolded out of our Drupal 8 & 9 Starter and as such you can easily download and try yourself as ddev is the only requirement. All commands are executed from inside the ddev container - so no special installation is required.
Follow the
installation
steps, and it should result with a Drupal site, and dummy content. Installation
should give you an admin link, but you can always grab a new one with ddev . drush uli.
Next, let’s create a static site with ddev robo snapshot:create. The Robo
command
is responsible for clearing Drupal’s cache, wget-ing the site and massaging it
a bit, cloning the Elasticsearch index, and is even nice enough to ask you if
you’d like to run a local HTTP server to see your new static site. Notice how
the search is still working, but if you look inside the network panel, you’d
see it calls a specific index. That’s our “snapshot” read-only index.

Go ahead and make some changes to your site. Add/ delete content, or even
switch the theme to Bartik. ddev robo snapshot:create once more. Note that you
might need to hard refresh the page in the browser to see the changes.
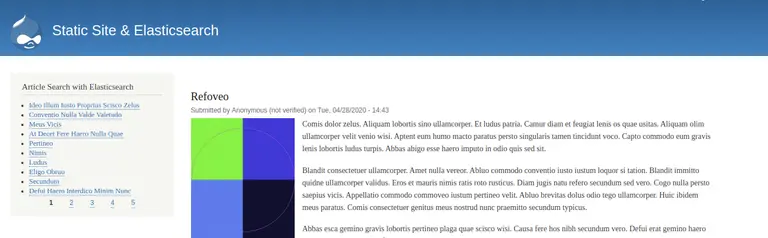
Elm Application
I’ve written the JS application for the search in Elm. We fetch data from the correct index URL, and then we show them in a paginated list. Like any app we’ve written in Elm, It Simply Works™.
As Elm is already bundled with the ddev container, we have a simple Robo command to watch for changes and compile them to the right place inside Drupal.
Two important things we do when we create a static site, is find & replace a JS variable which determines if Elm is operating in Drupal context, or static site context. With this knowledge we could have different functionality. For example, in the Drupal context, we could have shown an Edit link next to each result. At this same time, we also change the URL of the index, to the cloned one, so our JS app always calls the right URL.
Conclusions
I believe we have been successful with our attempts, and the requirements we had were well answered. Going with a static site provides considerable security, performance and stability gains. Having JS to communicate with a snapshot-specific Elasticsearch index wasn’t too hard and it’s working nicely. Naturally, in the demo repo the app is quite basic, but it lays the foundation for fancier features.
The biggest challenge of exporting the static site in a speedy manner boils down to excluding any user generated assets or pages. But still, some export time is always to be expected. Finally having Robo commands executed inside ddev is a convenient way to automate and share with other devs on the team.


Amitai Burstein
@amitaibu