Travis - The Need for Speed
In continuous integration, every second matters - and can even save a hasty merge. Explore ways to fine-tune Travis so that it hums along for your team.
Chances are that you already use Travis or another cool CI to execute your tests, and everyone politely waits for the CI checks before even thinking about merging, right? More likely, waiting your turn becomes a pain and you click on the merge: it’s a trivial change and you need it now. If this happens often, then it’s the responsibility of those who worked on those scripts that Travis crunches to make some changes. There are some trivial and not so trivial options to make the team always be willing to wait for the completion.
This blog post is for you if you have a project with Travis integration, and you’d like to maintain and optimize it, or just curious what’s possible. Users of other CI tools, keep reading, many areas may apply in your case too.
Unlike other performance optimization areas, doing before-after benchmarks is not so crucial, as Travis mostly collects the data, you just have to make sure to do the math and present the numbers proudly.
Caching
To start, if your .travis.yml lacks the cache: directive, then you might start in the easiest place: caching dependencies. For a Drupal-based project, it’s a good idea to think about caching all the modules and libraries that must be downloaded to build the project (it uses a buildsystem, doesn’t it?). So even a variant of:
cache:
directories:
- $HOME/.composer/cache/files
or for Drush
cache:
directories:
- $HOME/.drush/cache
It’s explained well in the verbose documentation at Travis-ci.com. Before your script is executed, Travis populates the cache directories automatically from a successful previous build. If your project has only a few packages, it won’t help much, and actually it can make things even slower. What’s critical is that we need to cache slow-to-generate, easy-to-download materials. Caching a large ZIP file would not make sense for example, caching many small ones from multiple origin servers would be more beneficial.
From this point, you could just read the standard documentation instead of this blog post, but we also have icing on the cake for you. A Drupal installation can take several minutes, initializing all the modules, executing the logic of the install profile and so on. Travis is kind enough to provide a bird’s-eye view on what eats up build time:
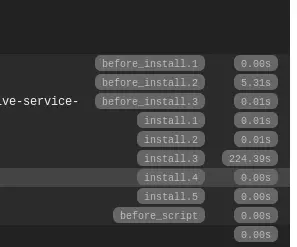
Mind the bottleneck when making a decision on what to cache and how.
For us, it means cache of the installed, initialized Drupal database and the full document root. Cache invalidation is hard, we can’t change that, but it turned out to be a good compromise between complexity and execution speed gain, check our examples:
Do your homework and cache what’s the most resource-consuming to generate, SQL database, built source code or compiled binary, Travis is here to assist with that.
Software Versions
There are two reasons to pay attention to software versions.
Use Pre-installed Versions
Travis uses containers of different distributions, let’s say you use trusty, the default one these days, then if you choose PHP 7.0.7, it’s pre-installed, in case of 7.1, it’s needed to fetch separately and that takes time for every single build. When you have production constraints, that’s almost certainly more important to match, but in some cases, using the pre-installed version can speed things up.
And moreover, let’s say you prefer MariaDB over MySQL, then do not sudo and start to install it with the package manager, as there is the add-on system to make it available. The same goes for Google Chrome, and so on.
Stick to what’s inside the image already if you can. Exploit that possibility of what Travis can fetch via the YML definition!
Use the Latest and (or) Greatest
If you ever read an article about the performance gain from migrating to PHP 7, you sense the importance of selecting the versions carefully. If your build is PHP-execution heavy, fetching PHP 7.2 (it’s another leap, but mind the backward incompatibilities) could totally make sense and it’s as easy as can be after making your code compatible:
language: php
php:
- '7.2'
Almost certainly, a similar thing could be written about Node.js, or relational databases, etc. If you know what’s the bottleneck in your build and find the best performing versions – newer or older – it will improve your speed. Does that conflict with the previous point about pre-installed versions? Not really, just measure which one helps your build the most!
Make it Parallel
When a Travis job is running, 2 cores and 4 GBytes of RAM is available – that’s something to rely on! Downloading packages should happen in parallel. drush make, gulp and other tools like that might use it out of the box: check your parameters and configfiles. However, on the higher level, let’s say you’d like to execute a unit test and a browser-based test, as well. You can ask Travis to spin up two (or more) containers concurrently. In the first, you can install the unit testing dependencies and execute it; then the second one can take care of only the functional test. We have a fine-grained example of this approach in our Drupal-Elm Starter, where 7 containers are used for various testing and linting. In addition to the great execution speed reduction, the benefit is that the result is also more fine-grained, instead of having a single boolean value, just by checking the build, you have an overview what can be broken.
All in all, it’s a warm fuzzy feeling that Travis is happy to create so many containers for your humble project:
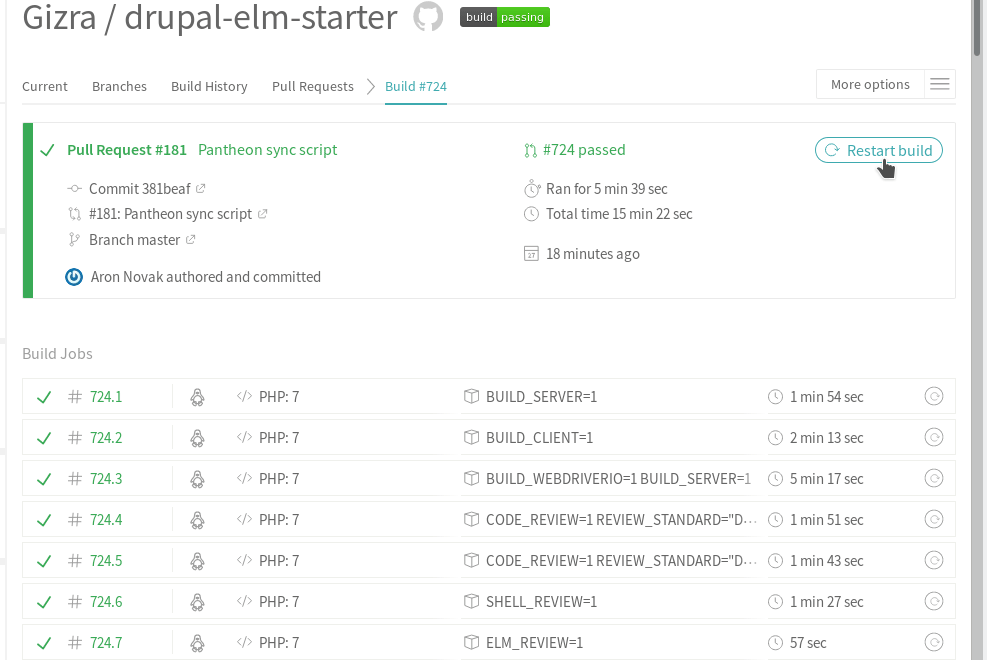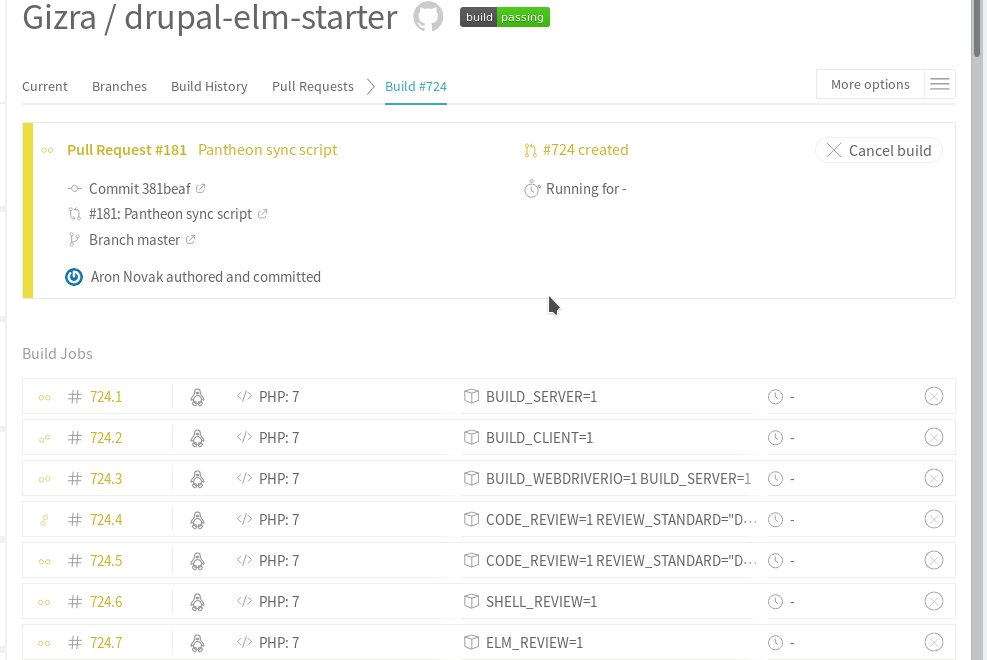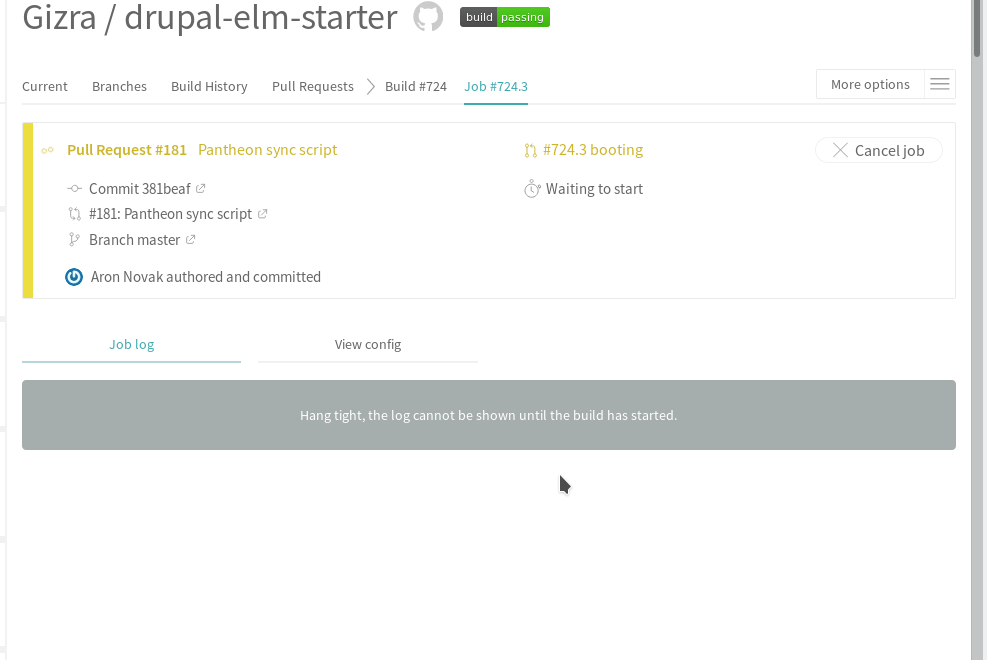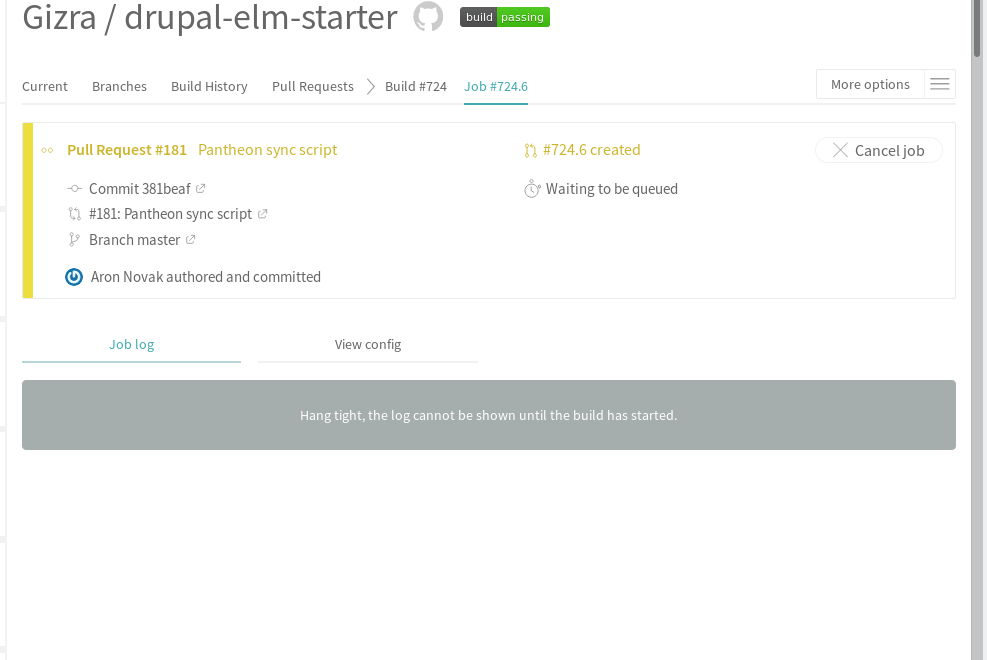
Utilize RAM
The available memory is currently between 4 and 7.5 GBytes , depending on the configuration, and it should be used as much as possible. One example could be to move the database main working directory to a memory-based filesystem. For many simpler projects, that’s absolutely doable and at least for Drupal, a solid speedup. Needless to say, we have an example and on client projects, we saw 15-30% improvement at SimpleTest execution. For traditional RMDBS, you can give it a try. If your DB cannot fit in memory, you can still ask InnoDB to fill memory.
Think about your use case – even moving the whole document root there could be legitimate. Also if you need to compile a source code, doing it there makes sense as well.
Build Your Own Docker Image
If your project is really exotic or a legacy one, it potentially makes sense to maintain your own Docker image and then download and execute it in Travis. We did it in the past and then converted. Maintaining your image means recurring effort, fighting with outdated versions, unavailable dependencies, that’s what to expect. Still, even it could be a type of performance optimization if you have lots of software dependencies that are hard to install on the current Travis container images.
+1 - Debug with Ease
To work on various improvements in the Travis integration for your projects, it’s a must to spot issues quickly. What worked on localhost, might or might not work on Travis – and you should know the root cause quickly.
In the past, we propagated video recording, now I’d recommend something else. You have a web application, for all the backend errors, there’s a tool to access the logs, at Drupal, you can use Drush. But what about the frontend? Headless Chrome is neat, it has built-in debugging capability, the best of which is that you can break out of the box using Ngrok. Without any X11 forwarding (which is not available) or a local hack to try to mimic Travis, you can play with your app running in the Travis environment. All you need to do is to execute a Debug build, execute the installation part (travis_run_before_install, travis_run_install, travis_run_before_script), start Headless Chrome (google-chrome --headless --remote-debugging-port=9222), download Ngrok, start a tunnel (ngrok http 9222), visit the exposed URL from your local Chrome and have fun with inspection, debugger console, and more.
Takeaway
Working on such improvements has benefits of many kinds. The entire development team can enjoy the shorter queues and faster merges, and you can go ahead and apply part of the enhancements to your local environment, especially if you dig deep into database performance optimization and make the things parallel. And even more, clients love to hear that you are going to speed up their sites, as this mindset should be also used at production.

Áron Novák
