Web Scraping: A Bit of Black Magic
Scraping from the web in practice: a recipe based on Drupal 8, Goutte and Feeds.
Recently we got an exciting task, to scrape job descriptions from various web pages. There’s no API, no RSS feed, nothing else, just a bunch of different websites, all using different backends (some of them run on Drupal). Is this task even time-boxable? Or just too risky? From the beginning, we declared that the scraping tool that we would provide is on a best effort basis. It will fail eventually (network errors, website changes, application-level firewalls, and so on). How do you communicate that nicely to the client? That’s maybe another blog post, but here let’s discuss how we approach this problem to make sure that the scraping tool degrades gracefully and also in case of an error, the debugging is as simple and as quick as possible.
Architecture
The two most important factors for the architectural considerations were the error-prone nature of the scraping and the time-intensive process of downloading something from an external source. On the highest level, we split the problem into two distinct parts. First of all, we process the external sources and create a coherent set of intermediate XMLs for each of the job sources. Then, we consume those XMLs and turn it into content in Drupal.
So from a bird-eye-view, it looks like this:
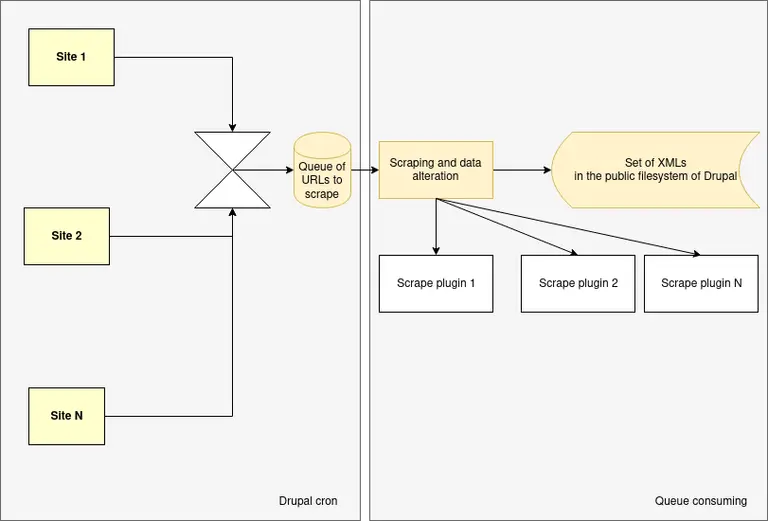
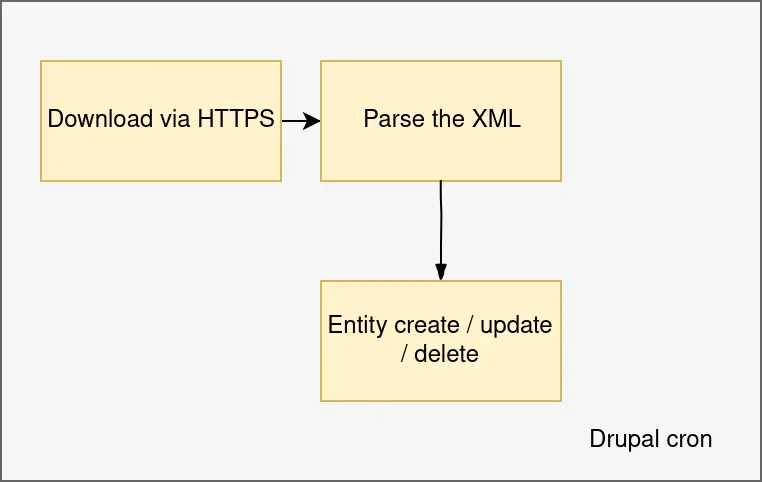
That was our plan before the implementation started, let’s see how well it worked.
Implementation
Scraping
You just need to fetch some HTML and extract some data, right? Almost correct. Sometimes you need to use a fake user-agent. Sometimes you need to download JSON (that’s rendered on a website later). Sometimes, if you cannot pass cookies in a browser-like way, you’re out of luck. Sometimes you need to issue a POST to view a listing. Sometimes you have an RSS feed next to the job list (lucky you, but mind the pagination).
For the scraping, we used Drupal plugins, so all the different job sites are discoverable and manageable. That went well.
What did not go so well was that we originally planned to use custom traits, like JobScrapeHtml and JobScrapeRss, but with all the vague factors enumerated above, there’s a better alternative. Goutte is written in order to handle all the various gotchas related to scraping. It was a drop-in replacement for our custom traits and for some sites that expected a more browser-like behavior (ie. no more strange error messages as a response for the HTTP request).
Content synchronization
For this matter, we planned to use Feeds, as it’s a proven solution for this type of task. But wait, only an alpha version for Drupal 8? Don’t get scared, we didn’t even need to patch the module.
Feeds took care of the fetching part, using Feeds Ex, we could parse the XMLs with a bunch of XPath expressions, and Feeds Tamper did the last data transformations we needed.
Feeds and its ecosystem is still the best way for recurring, non-migrate-like data transfer into Drupal. The only downside is the lack of extensive documentation, so check our sample in case you would like to do something similar.
Operation
This system has been in production for six months already. The architecture proved to be suitable. We even got a request to include those same jobs on another Drupal site. It was a task with a low time box to implement it, as we could just consume the same set of XMLs with an almost identical Feeds configuration. That was a big win!
Where we could do a bit better actually, was the logging. The first phase where we scraped the sites and generated the XML only contained minimal error handling and logging. Gradually during the weeks, we added more and more calls to record entries in the Drupal log, as network issues could be even environment-specific. It’s not always an option to simply replicate the environment in localhost and give it a go to debug.
Also in such cases, you should be the first one who knows about a failure, not the client, so a central log handling (like Loggly, Rollbar or you name it) is vital. You can then configure various alerts for any failure related to your scraping process.
However, when we got a ticket that a job is missing from the system, the architecture again proved to be useful. Let’s check the XMLs first. If it’s in the XML, we know that it’s a somehow Feeds-related issue. If it’s not, let’s dive deep into the scraping.
The code
In the days of APIs and web of things, sometimes it’s still relevant to use the antique, not so robust method of scraping. The best thing that can happen is to re-publish it in a fully machine consumable form publicly (long live the open data movement).
The basic building blocks of our implementation (ready to spin up on your local using DDEV) is available at https://github.com/Gizra/web-scraping, forks, pull requests, comments are welcome!
So start the container (cd server && ./install -y) and check for open positions at Gizra by invoking the cron (ddev . drush core-cron)!


Áron Novák

